")
Bienvenue dans l’univers fascinant des produits data ! Si les données sont le nouveau pétrole, alors le Data Product Manager (Data PM) est celui qui les...

IA : attention aux biais et problèmes éthiques
On se retrouve aujourd’hui pour parler IA spécifiquement sur un sujet qui ne cesse de prendre de l’importance depuis plusieurs mois : comment valider que les modèles d’intelligence artificielle sont corrects d’un point de vue éthique et ne génèrent aucune forme de discrimination ?
Ce sujet mérite en effet toute notre attention, car nous sommes amenés à proposer des solutions de plus en plus autonomes avec plus ou moins d’impact sur les utilisateurs finaux. Afin de contrôler le développement de ces modèles, la Commission européenne a d’ailleurs proposé des nouvelles normes de risques afin d’encadrer l’usage de ces technologies. En effet, à la suite de ces modèles avancés, les prises de décisions automatiques peuvent avoir plus ou moins de risques sur la société. Les solutions exploitant les intelligences artificielles devront désormais être classées selon leur risque ou dangerosité.
C’est pourquoi à AVISIA nous prenons les devants et travaillons activement sur ce point afin de vous garantir que nos modèles respectent un maximum de critères. Afin de bien comprendre les enjeux et les validations à mettre en place, il est important de maîtriser les risques possibles, à éviter lors de la construction de tels algorithmes. C’est ce que nous appelons généralement les biais.
Ces biais, qu’ils soient connus ou inconnus par les personnes construisant ces solutions, peuvent en effet être à l’origine de nombreuses dérives. Bien souvent ces biais ne sont relevés qu’après la mise à disposition au grand public et malheureusement certaines Intelligences peuvent conduire à de véritables problèmes éthiques comme l’exclusion de minorité dans l’usage de ces solutions.
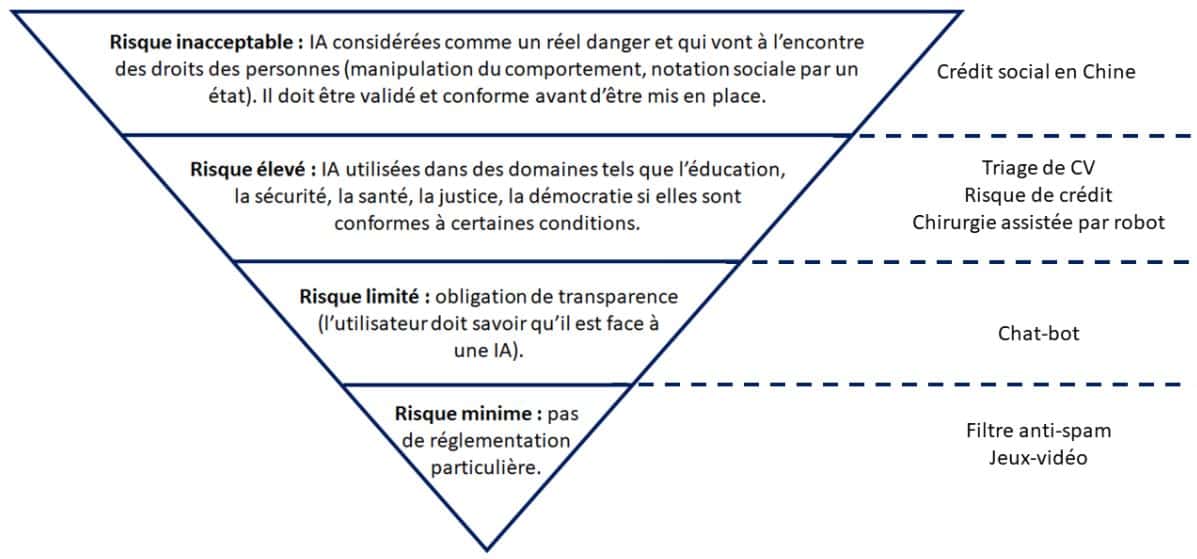
L’Union Européenne a décidé depuis le 21 avril 2021 de répertorier les systèmes d’IA de façon à leur imposer plus ou moins de règles en fonction de leur dangerosité. Les objectifs de ces mesures sont d’anticiper les possibles dérives de l’IA et veiller à ne pas porter atteinte à la vie privée de ses utilisateurs. Ils sont classés en quatre catégories : de risque minime à risque inacceptable en passant par risque limité et risque élevé. Voici ci-dessous les caractéristiques de chaque risque ainsi que quelques exemples associés :
Lors de la construction d’un modèle d’IA, il est important de bien prendre en compte les nombreux biais pouvant provenir des données, de l’algorithme ou même l’humain.
Les biais relatifs aux données sont principalement représentés par des données de mauvaise qualité ou non pertinentes à une étude. Nous distinguons ici deux biais :
Exemple : nous souhaitons prédire les ventes d’un produit à travers une campagne d’emails. Nous choisissons les 1000 premières réponses. Nous sommes face à un biais d’échantillonnage : pour le palier il faudrait tirer 1000 emails aléatoirement parmi l’ensemble des réponses. En effet, il est possible que les premiers répondants soient plus enthousiastes à répondre que des acheteurs ne souhaitant pas à tout prix le produit.
Exemple : reprenons l’idée de prédire les ventes d’un produit. Des personnes ne souhaitant pas acheter le produit seront moins susceptibles de répondre au mail, nous serions donc face à un biais de participation.
Exemple 1 : Facebook a utilisé un dataset contenant des métiers (comme variable cible) et des caractéristiques des personnes qui l’exerçaient pour entraîner son algorithme. Ce dernier conseillait des offres d’emploi différentes selon le sexe de l’utilisateur. La répartition démographique dans les données n’était pas équilibrée. Par exemple, pour un poste de comptable, la répartition (dans le jeu de données) était de 70 % pour les femmes et 30 % pour les hommes, il aurait eu tendance à conseiller les offres de comptable aux femmes. Cette recommandation irait à l’encontre de la vie réelle où, admettons, le poste de comptable est homogène.
Exemple : L’état de Washington a décidé de noter les enseignants pour équilibrer le niveau des élèves dans les différentes écoles : l’objectif est d’attribuer les meilleurs enseignants dans les écoles les plus faibles. Une enseignante très appréciée de sa direction et des parents d’élèves a été licenciée. Elle enseignait dans une classe avec beaucoup d’élèves en difficulté, les résultats étant moins bons qu’ailleurs, le modèle lui a attribué une note médiocre. Ici, des dimensions non-mesurables comme la difficulté d’un élève, la relation enseignant/élèves ; enseignants/parents d’élèves ne sont pas prises en compte dans l’algorithme. 205 autres enseignants de l’Etat de Washington D.C ont également été licenciés.
Exemple : une entreprise souhaite mettre en place un modèle pour trier les CV. Les développeurs pensent que les candidats ayant fréquenté leur école sont meilleurs que les autres et les favorisent dans la construction de l’algorithme : il s’agit d’un exemple d’un biais d’appartenance.
Exemple : Nous souhaitons construire un algorithme de reconnaissance de gestes : le modèle cherche à reconnaître si un individu dit oui avec sa tête en hochant celle-ci de haut en bas. Or, ce signe de la tête peut être interprété de manière différente selon les pays.
Les biais relatifs aux algorithmes se dessinent de deux façons différentes :
Exemple : l’application de reconnaissance faciale qui ne reconnaissait pas les personnes d’origine asiatique car elle avait très peu appris sur ce type de visages.
Nous avons synthétisé ces biais selon les différentes phases de réalisation du projet :

Une fois notre modèle construit en limitant au maximum les biais listés précédemment, nous pouvons passer à une phase de validation. A cette étape du projet, nous pouvons proposer une batterie de tests afin de contrôler que les probabilités restent similaires si l’on fait varier des variables exogènes au modèle, variables potentiellement discriminantes… De même, il est important de mettre en place une validation continue du modèle afin d’éviter d’éventuelles dérives qui pourraient apparaître dans le temps. Il est recommandé d’effectuer des contrôles continus sur un faible pourcentage des prédictions qui ont été réalisées. Enfin, l’intelligence humaine restera toujours celle à prioriser en cas de doute sur les résultats.
Si vous souhaitez plus d’exemples ou d’explications sur les biais existants, cette section du Crash Course de Google est particulièrement intéressant.
Afin de conceptualiser ces aspects théoriques, nous avons créé un exemple de toute pièce. Dans cet exemple, nous partons de l’hypothèse que construire une intelligence artificielle pourrait nous aider à déterminer, voire à terme, choisir la prochaine Miss France du célèbre concours de beauté annuel. Pour arriver à notre objectif, nous avons nourri notre algorithme des images des précédentes candidates à l’élection puis labellisé celles qui avaient atteint le top 5 (label 1) ou non (label 0). Nous allons voir étape par étape les différents biais qui sont ressortis d’une démarche « naïve » et inattentive à l’éthique.
Typiquement, après toutes ces explications, nous pourrions obtenir ce genre de résultats :

D’après les probabilités, une personne d’origine asiatique (peu fréquente au concours Miss France) dont nous avons passé un set d’images à notre modèle, aurait moins de chances de gagner le concours qu’une personne de type européen a priori sans critères de beauté apparents. Ces résultats simulés prouveraient l’existence d’un ou plusieurs biais soulevant ensuite de nombreuses questions éthiques si ce projet d’intelligence artificielle arrivait, à terme, à remplacer les choix humains. Même si les décisions humaines ne sont elles aussi pas toujours éthiquement correctes dans la vraie vie, un algorithme ne doit pas les reproduire.
Comme nous l’avons, tout au long de cet article, il y a beaucoup d’étapes à valider afin de pouvoir exploiter concrètement et sereinement une intelligence artificielle qui est prête à prendre des décisions ou à réaliser des actions plus ou moins impactantes pour l’individu ou la société. On pourrait penser que ces algorithmes apprennent seuls et prennent leurs décisions seuls : en réalité c’est bien l’Homme qui dicte à la machine ce qu’elle doit apprendre puis décide des actions à effectuer selon le résultat obtenu. Dire qu’une IA est “éthique” résulte donc dans la capacité à prendre du recul sur chacune des étapes de son projet afin de ne pas reproduire d’éventuels phénomènes de société ou décisions humaines qui, elles, n’étaient peut-être pas éthiquement correctes.
AVISIA travaillant depuis plusieurs années autour de cette thématique, nous avons donc lancé différents travaux afin de pouvoir proposer, sereinement, des solutions d’intelligences artificielles à nos clients. Pour nous, cela passe notamment par :
Nous espérons que cet article soulèvera d’éventuelles interrogations et vous incitera à vous poser des questions lors de la création de vos prochains scores. Quelques doutes subsistent encore notamment sur la frontière entre une variable dite « éthique » ou non : nous pouvons facilement comprendre que la couleur de peau ou le genre de la personne sont bien évidemment des champs sensibles sur lesquels il faut faire attention. Qu’en est-il des variables comme le département de résidence, lieu de naissance, l’âge, etc. ? Quoiqu’il en soit, chez AVISIA ces sujets méritent toute notre attention et alimenterons certainement nos prochains débats autour de l’intelligence artificielle. Nous serions aussi ravis d’en discuter avec vous !


Data contact